Machine Learning con Java
01 Nov 2016En la pasada PyconEs en Almería, Cajamar tuvo la gran iniciativa de hacer un Datathon. Esto es, un campeonato sobre machine learning y minería de datos.

En su web se puede ver toda la información disponible sobre el reto.
Tuve la feliz idea de participar, contra todo pronóstico, sólo y usando lenguaje Java. Y opté por el reto predictivo por ser una materia que me interesa más, y por que era donde tenía una remota posibilidad de llegar a algo sin ayuda. Mi conocimiento previo en esta materia era totalmente nulo, así que tenía mucho que aprender y que investigar.
Con tan poco tiempo por delante decidí usar lenguaje Java porque me siento mas cómodo por ahora con él.
Mi impresión fue que, tal y como me figuraba, a día de hoy Python se lleva la palma en cuanto a funcionalidades científicas y desarrollo de librerías punteras, como es el caso del Machine Learning.
 Realmente mi experiencia general fue la sensación de abrir el gran melón del Big Data. Había tanto que investigar, aprender y mirar que lo que más aprendí fue todo lo que me queda por saber. También hay que aprender a trazar un camino seguro en el aprendizaje, algo que ya de por sí es bastante, y os aseguro que en mi caso va a pasar por Python/Jupyter con sus librerías, IBM Watson, y como no, Tensorflow.
Realmente mi experiencia general fue la sensación de abrir el gran melón del Big Data. Había tanto que investigar, aprender y mirar que lo que más aprendí fue todo lo que me queda por saber. También hay que aprender a trazar un camino seguro en el aprendizaje, algo que ya de por sí es bastante, y os aseguro que en mi caso va a pasar por Python/Jupyter con sus librerías, IBM Watson, y como no, Tensorflow.
Pero volviendo a mi aventura, también hay vida inteligente en Java, no podía ser menos. Primero encontré una pequeña librería, que luego resultó obsoleta, pero cumplió su papel de iniciarme en este campo: Java-ML Muy simple y asequible. Tiene un pequeño tutorial para empezar y romper el hielo. Ya de primeras no lo veía adecuado para el gran set de datos que Cajamar había preparado, pero el objetivo principal era aprender de qué iba todo esto del Machine Learning.
Cuando empieza a entrar en materia veo que hace uso de otra librería que se llama Weka , de la Universidad de Waikato, Nueva Zelanda.
Después de una pequeña investigación en Google me di cuenta que Weka está referenciada como de lo mejor en Machine Learning en Java, y desde la Universidad se ocupan de mantenerla actualizada.
No solo eso, Weka es principalmente un programa con su interfaz gráfico totalmente completo para hacer minería de datos e investigaciones científicas con Big Data. Por lo que he visto y usado es muy completa y funciona muy bien.

Las visualizaciones y la UI no son de lo más actual pero cumplen su función a la perfección

El programa está muy documentado y hay libros para sacarle el máximo partido. De hecho, la librería Java que dejan para su uso directamente con código me pareció relegada a un segundo lugar en importancia a nivel de tutoriales y documentación.
Por desgracia la mayor parte del poco tiempo que tuve la pasé preparando los datasets. Weka puede importar diferentes tipos de datasets, pero también usa su propio formato que a mi me pareció muy buena idea usar. La extensión ARFF es un dataset en modo texto pero donde se define de manera explícita en el encabezado que tipos de datos se van a manejar. Muy adecuado para que un usuario vea con un simple vistazo qué tipo de información va a manejar.
Mis resultados no fueron malos, pero me faltó tiempo para terminar el código y presentar las cifras de manera adecuada.
Opté por un modelo RandomForest, ya que los datos que tenía eran una mezcla de continuos y discretos, y entre la gran variedad de opciones me pareció la mejor (en esto coincidí con la mayoría de participantes).
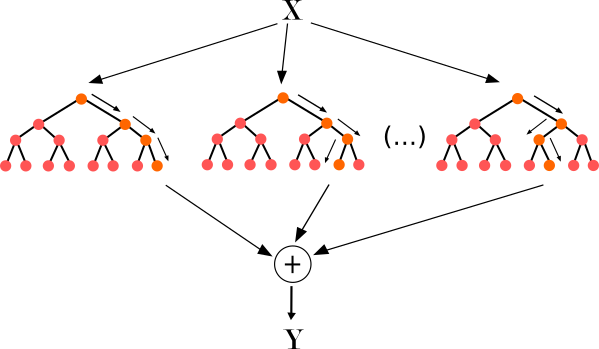
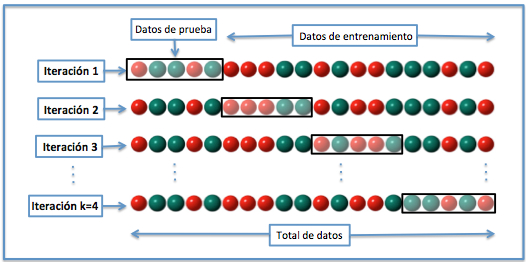
En el Cross Validation que llevé a cabo los resultados de previsión de predicción del modelo no eran malos: un 0.79 Aunque hay que tener cuidado con el uso de esta herramienta ya que solo es orientativa y hay que tener muy en cuenta la relación de los datasets entre sí.
Como resultado de los experimentos, y determinar a los ganadores, los jueces pedían, aparte del set de prueba con los datos predichos, gráficas explicativas como la curva Roc. Este gráfico es perfecto para comprobar la eficiencia de predicción en el modelo que hemos entrenado.
 AUC = Area Under Curve
AUC = Area Under Curve
En github he puesto un repositorio con lo que conseguí hacer en un par de noches de sprint. Y hay mucho mas código que se queda en el tintero, mas feo incluso si cabe, que realizé para modificar los datasets tanto en entrada como salida y poder trabajar con los datos sin otras aplicaciones. Este quedará para la posteridad como un pequeño Frankenstein. En el futuro mis esfuerzos irán de la mano de Python, y algo de R.
Por último me quedé con ganas de aportar mi granito de arena al proyecto Weka (al final le acabé cogiendo el gusto), y como me gustó esto de encontrar la solución al problema planteado, me quiero hacer una aplicación que genere Datasets con un patrón oculto para seguir entrenando mis habilidades como Data Miner.
La idea es escribir un encabezado de archivo de datos Weka,

y que el programa genere tantas filas como queramos siguiendo un patrón generado mediante unas reglas ocultas. Lo interesante de esto es generar datasets, de tantas filas o columnas como queramos, con un porcentaje de casos positivos mayor o menor según se quiera, y con los set de entrenamiento, test y resultado listos para hacer las comprobaciones.
Me parece buena idea para aprender a escoger, entre todos los modelos matemáticos que hay disponibles, el mas adecuado según las características de cada Datatset.
Espero desarrollarlo en los próximos meses, se puede encontrar en github y si alguien quiere colaborar es bienvenido ;)
Saludos :D
PD: por cierto no os perdais los trabajos de los ganadores que son de primera calidad